こんにちは。
鈴木はるかです。
今回は、SEOの基本中の基本、クロールについてです。
あとこの言葉を見た瞬間、何か言いたくなるベテランさん。
それについても、詳しく解説したいと思います。
それでは基本から、おさらいしてみましょう。
検索エンジンの基本
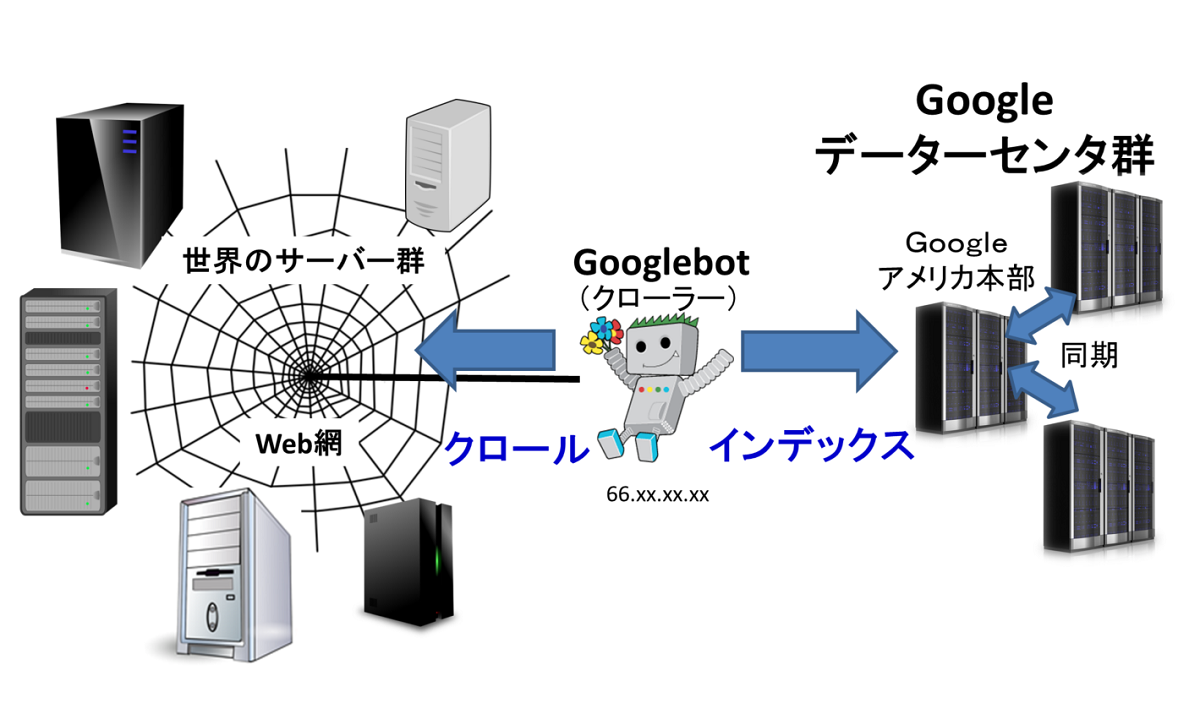
Googleは、クローラーというものを使い、サイトを網の目の様に細かく巡回しています。
クローラーというと特殊なものに思えますが、そうではありません。
一般的なブラウザ(2019年6月19日現在でchrome75程度の機能)でサイトを見ているといっても良いでしょう。
ブラウザのユーザーエージェントはリンクの通りで、端末はNexus5xです。
モバイルファーストインデックスに移行されているサイトは、横サイズ640pxの解像度でアクセスしてきます。
つまり、ViewPortタグが指定されており横サイズ640pxに収まっていればモバイル対応とみられるわけでです。
(その他、タグなどの条件はあります)
ただし、320pxなどで正しく表示できるか、恐らく別のエージェントで見ていると思いますので、くれぐれもgooglebotの仕様を満たしていればいいという検索エンジン最適化の思想をしないでください。
顧客のUXを最優先することを目指します。
クロールとインデックスの模式図
クローラーは、別名スパイダーとも言います。
蜘蛛の巣に見立てたウェブ網を、細かく巡回してサーバー内のコンテンツを抽出するからです。
抽出されたコンテンツは、整理されGoogleのデーターベースにインデックスされます。
データーセンターは、世界の複数の箇所にあり、極力同期するようにしています。
インデックスされたコンテンツは、検索画面に入力されたキーワードから関連性の高いコンテンツを見つけてランク付けします。
このような一連の動作は
- クロール(サイトを巡回しデータを取得するのが仕事)
- インデックス(データを整理して格納するのが仕事)
- ランキング(入力クエリに対する順位を付けるのが仕事)
という3つのフェーズで表されることが多いです。
おのおの役割が決まっていて、なすべき仕事があります。
3つのフェーズのうち、ひとつでも阻害されると、検索結果に表示する事が難しくなります。
たとえば、robots.txtなどでクロールを阻害すると、インデックスするのが難しくなります。
インデックスされなかったら、検索結果に表示することはできません。
クロールは正常に行えても、meta命令で「noindex」を指定してコンテンツの表示をブロックしたり、同じコンテンツを複数のURLで作成する「重複コンテンツ」が発生した場合も、インデックスされないので、検索結果には表示されません。
クロール、インデックスが正常でも、検索エンジンに入力するクエリとコンテンツの関連性が無いと、検索結果には表示されません。
このように、クロール、インデックス、ランキングは、検索エンジンの基本動作で、どれかひとつ欠けても検索エンジンに表示する事ができなくなります。
クロールバジェットとは
Googlebotが、サイトをクロールするための上限のリソースと言っても良いです。
ただし「Googlebotやサイト」で一意に決められるものではなく、ページやサイトごとに変化します。
私は定義を以上としましたが、Googleはクロールバジェットという言葉使っていません。
なので、定義も存在しません。
このことは、比較的新しいブログに書かれています。
私の記事では、この公式ブログの内容をより深く追求することです。
さらに、上述の「公式ブログ冒頭」やSEOのベテランに気にする必要は無いと言われ盲目的になっているサイト運営者に気づいてほしいという気持ちも入っています。
真のベテランは、間違った言葉を使ったり解釈を発見したら、丁寧に説明して是正するのが持続的なウェブエコシステムだと思うのです。
しかし、従前からSEOに携わっているアンチな方から見ると「クロールバジェット」という言葉が出た瞬間に親でも殺されたかのように「あなたには関係ありません」と言われたりします。
クロールバジェットは、単なるクロール割り当て量です。
これは、全てのウェブマスターが知り、理解し、コントロールするべきだと、私は思っています。
くれぐれも、大規模サイトしか関係ない、気にする必要は無いなどの言葉に、目を閉じることがないようにしてほしいです。
全てを知ってから目を閉じるのと、知らずに目を閉じるのは全然違います。
クロールバジェットとクロールレート
クロールレートはサーチコンソールのヘルプでは、
クロール頻度
と訳されています。
しかし私はウェブマスターブログに従いクロールレートという用語を使います。
クロールレートもクロール頻度も同じものです。
クロールレートは正式な用語で、昔のサーチコンソールをご存じの方は、多いと思います。
クロールレートの説明
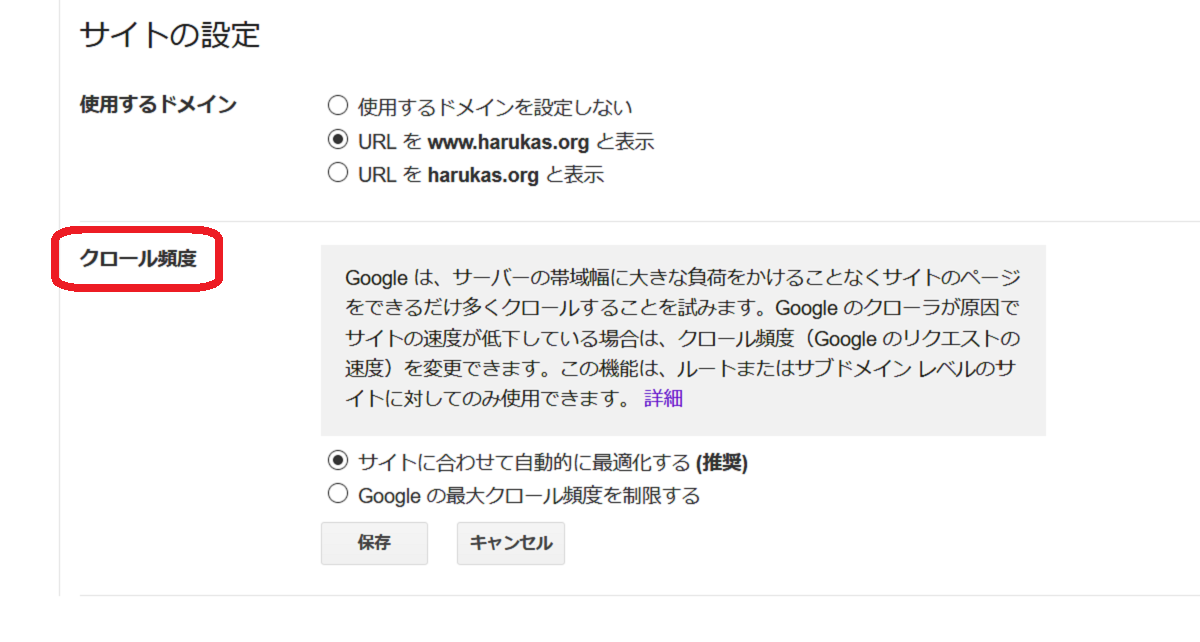
この設定は、新しいサーチコンソールには実装されておらず古いサーチコンソールのみ設定が可能です。
クロールは、SEOの基本という話をしています。
その基本的なものを、よく意味が分からず触るものではありません。
私はGoogleの説明どおり、クロールレートを変更する事はお勧めしません。
その理由は、クロールレートを決めるアルゴリズムが、非常に優秀だからです。
もうひとつ言うなら、Googleのクロールで問題が発生していると突き止められるベレルの技術者であれば、サーバーを強化したり調整したりしているはずなので、小手先の調整など意味が無いからです。
ではクロールレートについて、詳細に説明します。
A,B,Cの3ページをクロールする様子を表しています。
クロールレートについて
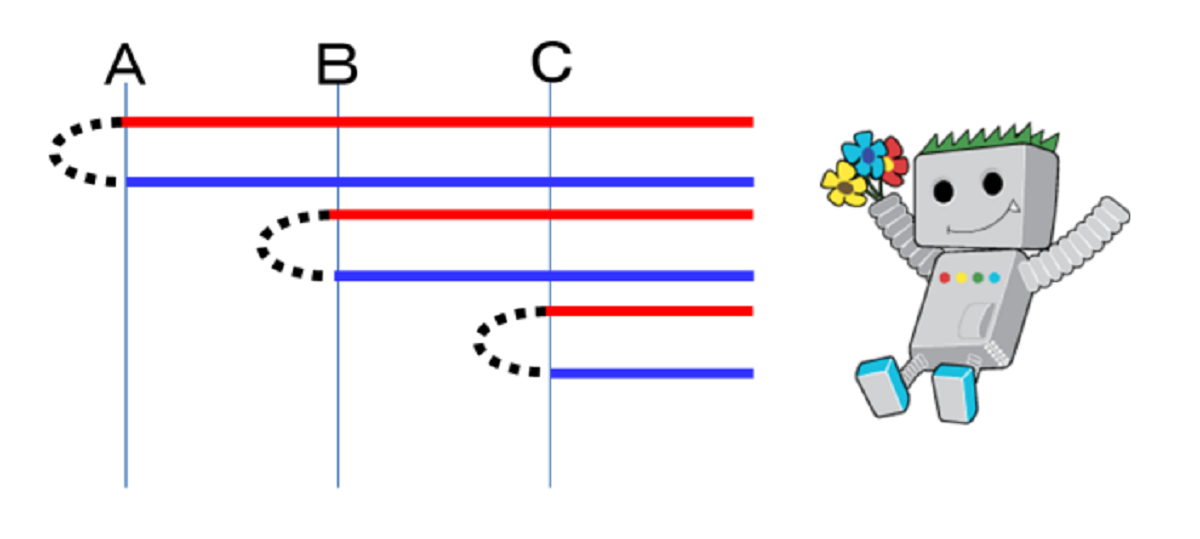
添付の赤線が、サーバーに対するリクエストで、青線がレスポンスです。
黒色の「てんてん」で表している時間が、サーバーの処理時間です。
クロールレートは、赤線の間隔の最小値です。
単位は、回数/秒でGooglebotが1秒間のうちに何回リクエストを行うかです。
通常サイト(数千ページ未満)では、最大1~30程度の間で自動設定されていると思われます。
クロールレートは、サイトをクロールするために必要なリクエスト回数の最大値です。
クロールバシェットは、サイトをクロールするための割り当て量の事です。
「リクエスト回数の最大値」と「割り当て量」ですから、この二つは全く違うものです。
混同しないようにしてください。
割り当て量を上限として、リクエスト回数の最大値以下でクロールする・・・というのが正しい理解です。
(超難しい表現ですねw)
クロールレートが微分値、クロールバジェットが積分値という考え方もあると思います。
(余計わからんワイww)
では、クロールレート(リクエスト回数の最大値)の決め方について説明します。
私は小さい頃から、外食のラーメンが好きでした。
約3週間に1回は、外に食べに連れて行ってほしいと言っていました。
その間隔を1週間や、毎日にしてしまうと、おそらく両親は怒るでしょうね。
育てられていくうちに、3週間に1回という私の家庭にとって最適な回数を算出していったのです。
もちろん、別の家庭では、毎日外食ラーメンでもOKな方もいるでしょうし、ラーメンは1年に1回以上食べさせない家庭だってあると思います。
このように、家庭によっても変わってきます。
クロールレートも全く同じで、さまざまなアルゴリズムによって、最適な数値を算出しています。
具体的には、サイトのパフォーマンス(サーバー処理速度)を見ています。
すぐにレスポンスを返す高速のサーバーであれば、どんどんクロールの間隔を狭めていきます。
クロールの間隔を狭めることは、単位時間内のリクエスト回数を増やすことです。
そして、サイトのコンテンツを表示するのに、著しい時間がかかったり、サーバーが5xxを返却すると、上限だと判断します。
ただし、一回の挙動で判断したりしません。
複数の挙動や調整で、最大値を獲得します。
この意図は非常に簡単な考え方です。
一般訪問者がサイトを閲覧することが最優先なので、その妨害にならないように最適な数値を探しているという訳です。
クロールレートの単位は、回数/秒で1秒間にリクエストできる最大の回数です。
クロールバジェットの単位は回数で、ページごと、クローラーの種類ごとに間隔は異なります。
Googleがサイトをクロールする目的
クロールがなぜ必要か、簡単に答える事が出来ますか?
クロールが必要な理由は、次の2点です。
- 新しいコンテンツを探す
- サイトの変更部分探す
Googleは常に最新の検索結果で、最新の情報を表示しようとしています。
そのためには、コンテンツを提供するサイトの情報を素早く入手する必要があります。
私たちの情報を素早くインデックスするために、クロールしているのですね。
1は、RSSで情報を送ったり、Pingを送ったり、サイトマップPingを送ったりします、
このような仕組みを実装しているサイトは、Googleのクロールの意図を理解しており、サイトを更新したら素早くGoogleにクロールしてほしいと考えるウェブマスターだと思います。
2のサイトの変更は、厳密には2つあります。
ひとつが、サイトの構成変更で、もうひとつがコンテンツの変更です。
サイトの構成変更とは、内部リンクやサプリメンタリーコンテンツ(グローバルメニューやサイドバー、カテゴリーリンク等サイトのコンテンツを見やすく巡回しやすくする補助的なコンテンツ)の設置や変更などです。
補助的なコンテンツを追加する事により、サイトの価値やキーワードの価値が向上して、ランキングに影響を与えるため、クロールして最新の情報に更新しようとします。
コンテンツの変更は、いわゆるリライトなどで古い記事を最新の情報に合わせて追加修正したり、削除したり、復活したりする事です。
同じく、ランキングに影響するため、素早くインデックスしようとします。
以上がGoogleがサイトをクロールする目的です。
目的のためにどのような頻度でクロールするか?というのが気になりませんか?
実はこれ、サイトごとに違いサイトの特性によっても違います。
クロール周期が早いサイト
・更新周期が早い(ブログ、ニュースに関係ない)
・ニュースサイト/トレンドブログ
・高品質コンテンツを提供している(人気が高い)
クロール周期が遅いサイト
・更新周期が不定期で長い
・低品質コンテンツ(人気が低い)
という傾向があります。
ただし、クロールとランキングは別物です。
高品質サイトで人気が充分高くても更新が不定期(1ヶ月とか)であれば、クロール数は少ないです。
なので、決してクロールの数=品質ではない事に注意してください。
Googleによるサイトのクロールは、新しいコンテンツが作成されたか?、何か変更箇所はないか?を見つけるため、定期的に行っています。
このような受け身だけではなく、ウェブマスターからクロールを指示する事も可能なのです。
方法は次の通りです。
ウェブマスターが明示的にクロールを要求する方法
サイトマップを更新して通知する
Googleは、クロールバジェットの範囲内で定期的にサイトマップを閲覧しています。
サイトマップに、新しいURlが追加されたり、xmlサイトマップを送信していてlastmodを通知している場合は、それを発見し次第、クローラーが飛んできます。
ここで大多数のウェブマスターが勘違いしていることを話します。
サイトマップを更新したからと言って、そのサイトマップがクロールされない事には、新しいコンテンツや変更したコンテンツを見つけることはできません。
サイトマップを更新したら、サイトマップをクロールしてもらうため必ず送信を実行してください。
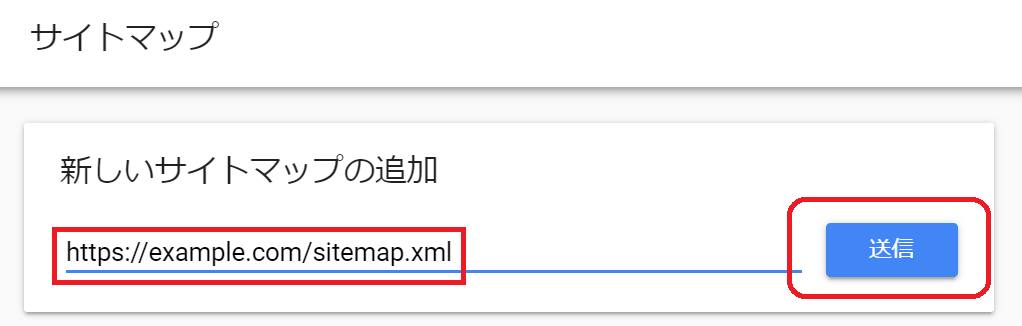
送信方法は2種類あります。
ひとつがサーチコンソールで、URLを指定して送信する方法です。
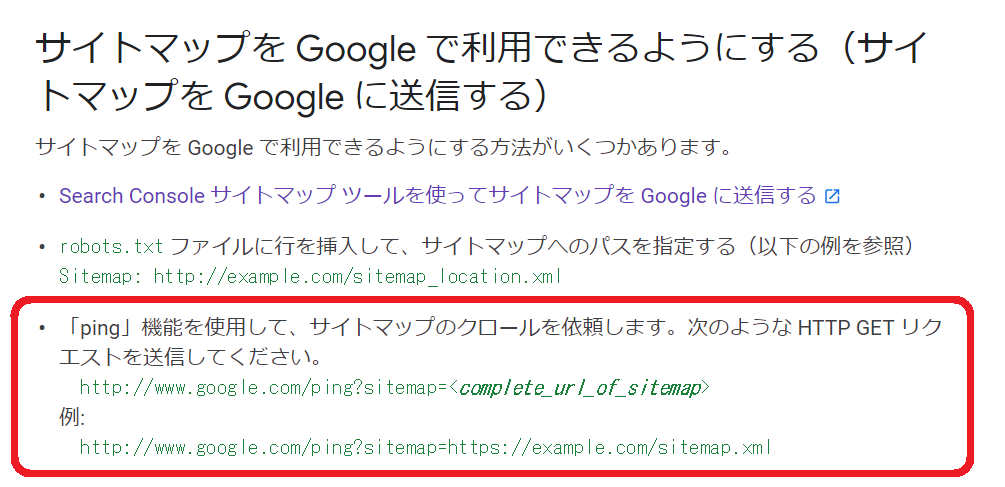
もうひとつが、サイトマップPingを打つ方法です。
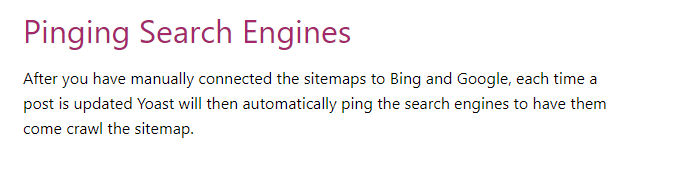
ちなみに、WordPressでプラグインを使っているウェブマスターは、焦る必要はありません。
例えば、YoastSEO プラグインは、サイトマップを更新すると自動的にPingを送信してくれます。
ということで、ご自分の使っているサイトマップツールが、正しくPingを送信するのか、今一度確認してみてください。
自作の方はPing送信の機能は、必須です。
情報サイトにPingを打つ
以下は、使えるかどうか分かりません。
こういうサイトにブログ更新のPingを打つとそれぞれの情報サイトに更新情報が掲載され、それを元にGoogleやBingがたどってくれます。
ただし、私はあまり効率的とは思いませんけど^^;
WordPressからリンクがありますが、補償はしていません。
http://rpc.pingomatic.com/
http://rpc.reader.livedoor.com/ping
http://ping.freeblogranking.com/xmlrpc/
http://api.my.yahoo.com/RPC2
http://ping.blo.gs/
http://rpc.weblogs.com/RPC2
http://rpc.pingomatic.com/
http://xping.pubsub.com/ping/
http://ping.ask.jp/xmlrpc.m
もし、WordPressで設定したい場合は、設定→投稿設定の一番下にあります。
私は、この方法ではなく1項のYoastSEOのサイトマップ送信をお勧めしますw
サーチコンソールのURL検査でリクエストする
サーチコンソールのURL検査ツールを使います。
URLを入力したら、「ページを変更しましたか?」という表示が出ますので、、そこで「インデックス登録をリクエスト」します。
従前のFech as Googleと同等機能で、すばやくインデックスを行ってくれますが、これは恒久的に使用するものではありません。
正しくサイトマップを更新して、Pingを打つのが通常の運用です。
その他の方法
紹介した内容以外にも、Indexing API を使用する方法があります。
現在は、求人情報しかサポートされていません。
しかし今後は、こういったAPI制御が一般的になると予想します。
クロールバジェットに影響のある行為について
クロールバジェットについておさらいします。
クロールバジェットは、クロールの割り当て量の事です。
割り当て量なので、クロールするほど減っていき、最後は重要なページすらも、クロールしなくなります。
重要なページとは、新規コンテンツやサイトにとって重要な変更したページの事です。
重要なページがクロールされなくなるのは大問題です。
大抵は、不用意な設定をした数千ページ以上持っている大規模サイトで発生します。
しかし私が主張したいのは、小規模サイトでも影響が出る可能性があるという事です。
Googleのゲイリーさんが言っている
「クロール バジェットとは、ほとんどのウェブマスターの方々にとって気にすべきものではない、ということです」
も、正しいと思います。
クロールバジェットはあくまでクロールに対しての用語です。
クロールとランキングは、直接関係ありません。
なので、ボクのサイトはクロールバジェットを減らされて低い順位を付けられている。
などという大誤解だけは絶対にしないでください。
クロールに問題が発生するときは
・新規ページがすぐにインデックスされない
・ページを更新してもすぐに反映されない
・良い方に作用するはずのアルゴリズムが機能するのが遅い
などが発生するだけです。
逆にこれだけの影響なのです。
キーワードに対しての順位が変わるわけではないことは、本当に理解願います。
私のブログで問題を発見したとしても、改善の優先順位の付け違いをしないでくださいね。
さて、それでは公式ページでゲイリーさんがクロールバジェットに影響があると書いているものをみてみましょう。
影響の高い順になっているようです。
- ファセットナビゲーションとセッションID
- サイト内の重複コンテンツ
- ソフトエラーページ
- ハッキングされたページ
- 無限のスペースとプロキシ
- 質の低いコンテンツやスパム コンテンツ
- 鈴木はるかが考えるクロールバジェットの影響
※7は私が追記しました。
ファセットナビゲーションとセッションID
ファセットナビゲーションは、ECサイトでシャツの色やサイズなどを選ぶ際、複数のパラメータを指定して、検索出来るようにしている便利な機能です。
しかし、次々にパラメータが追加されれるため、どのパラメータが新しいページを表しているのかが検索エンジンにわかりにくくなります。
例えば、Tシャツのサイトを構成していて、新しいブラウスのコンテンツを追加したとします。
すると、パラメータ設計によっては、Tシャツの色が増えたのか、ブラウスという新しいカテゴリが増えたのか理解できなくなり、結果としてブラウスがインデックスされるのが非常に遅くなったりします。
これは、小規模のECサイトでも発生する問題です。
Googleではベストプラクティスとして、ページの構成や商品自体が違うものは、パラメターではなくURLを分けるのが良いとしています。
もし、パラメータに応じて次々にページが増えていくサイトを設計する場合、何をURLにするか、何をパラメータにするか、あらかじめ設計段階で整理しておく必要があるのが分かります。
セッションIDは、ログインしセッションを確立したら、その情報をURLに追記する手法です。
また、それ以外にもボタンを押されてコンバージョンするまでを追跡したりするパラメータを設定することがあります。
このとき、大抵は同じコンテンツでURLが違うという「重複コンテンツ」になることが多いです。
重複コンテンツの場合、同じページをいくつもインデックスすることはありませんので、こういうパラメータがついたURLは
重要度が低い=低クロール
になり、クロールバジェットを減らされます。
クッキーを上手く使ったり(かといってITPがw)リダイレクトする方法などが紹介されています。
サイト内の重複コンテンツ
コンテンツが同じなのに複数のURLでアクセスできるものを重複コンテンツと言います。
ECサイトなどで、色が複数あったり、トラッキングパラメータを付けたりさまざまな原因で発生します。
同じコンテンツというのは、Googlebotも理解しています。
古いサーチコンソールのURLパラメータを見ると「googlebotにより判断」のように適切にクロールを調整されます。
私は、URLパラメータで「googlebotにより判断」になっているパラメータは、適切にクロール周期を調整されているので、こちらで触る必要はないと思います。
同じコンテンツに複数のURLでアクセス出来る場合、そのページのクロールバジェットを減らされてしまうので、canonicalや301を正しく設置して正規URLがあることを通知するのが良いと思います。
重複コンテンツについては、canonical、301リダイレクトが上手く出来ていれば、全く問題ないと思っています。
ただし減ったクロールバジェットが復元するという意味ではありません。
サイト構成やパラメータ構成をGoogleが理解しやすくなり、今後のインデックスに悪影響を及ぼす可能性が減るという意味です。
小規模サイトで、運営者が気づかず発生する問題を説明します。
例えばhttpとhttps双方でアクセスできるとします。(301はなく、canonicalも無いか不正:自分参照)
するとhttpのクロールとhttpsのクロールで同じサイトでも2倍のクロールが発生します。
実際2倍もクロールしないのは、自明ですよね。
単にクロール数(クロールバジェット)を減らされておしまいです。
こういうサイト全体で発生するミスは、いかに小規模サイトでも気をつけなければなりません。
なお、https関連だけではなく、www有無も同じです。
検出は、インデックスカバレッジレポートで
「重複しています。ユーザーにより、正規ページとして選択されていません」
「重複しています。送信された URL が正規 URL として選択されていません」
「重複しています。Google により、ユーザーがマークしたページとは異なるページが正規ページとして選択されました」
の項目を重点的に確認します。
全体のインデックス数に比べ、数パーセント程度なら問題はありません。
しかし、大量に発生している場合は、クロールバジェットに影響がありますので、原因を特定したほうがよいです。
ソフトエラーページ
ソフトエラーという言葉を使っていますが、今はソフト404に統一されています。
ソフト404を簡単に説明すると、HTTPレスポンスは200(正常応答)を返して、ページは「見つかりません」など価値がないものを表示する事です。
Googleは、価値のあるものをインデックスして検索エンジンに表示しようとします。
それなのに、暗号化されて解読できないデータや、見つかりませんや、また、トップページを別のURLでも表示したりすると、ソフト404を検出します。
ソフト404の確認方法
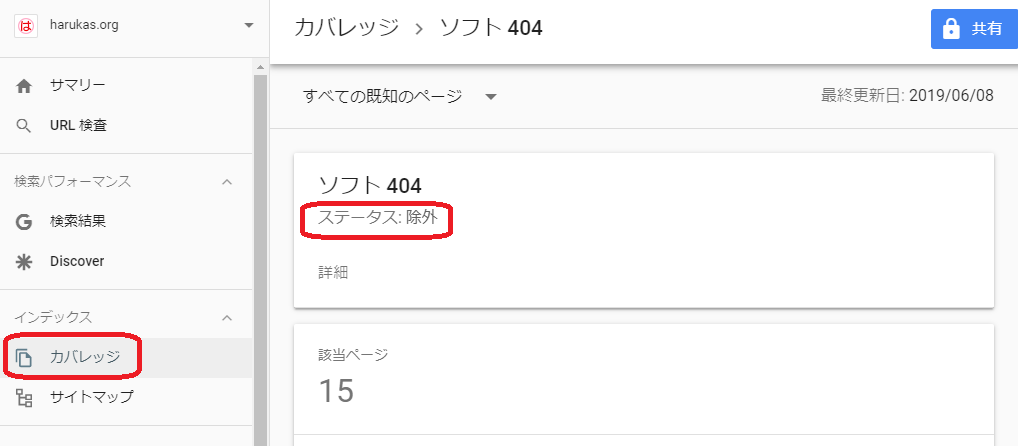
ソフト404は、サーチコンソールのカバレッジから、除外を選択してソフト404を選びます。
ソフト404の項目が無い場合は、検出してませんので問題ありません。
表示されているURLを確認してページを表示してみてください。
エラーページや、他のページと同じものがあったら要注意です。
問題は、大量に発生している場合です。
インデックス数の半分とか、1/4とかが大量だと思います。
なぜ、大量発生が問題かというと、通常の404(みつかりません)と大きく違うからです。
404見つかりませんは、コンテンツが見つからない場合で、処理は特にありません。(404は後述します)
しかしソフト404は、サーバーが正常応答した通常コンテンツを、Googleが別のページと同一ではないか?、エラーページではないか?などをアルゴリズムで算出して判断しています。
従ってソフト404が大量に発生してしまうと、そのサイトに膨大な処理(Google自体のリソース)を消費してしまいます。
ソフト404が大量にある場合、クロールバジェットを減らされて通常のクロールに影響が出てしまうのです。
繰り返しますが、大量に発生しなければ気にする必要は無いですよ。
私が解決したトラブルで多かったのが、下位ページをトップページにリダイレクトしていたとか、トップページのコピーを下位ページで表示していた等です。
純粋に404ページを200で表示しているサイトもありました。
404ページをカスタマイズして、独自の404ページを表示する事は推奨されます。
しかし、そのような前向きの姿勢なのに404ページが200になっていたり301になっていたりするのを多数確認しています。
カスタマイズされている方は、必ずHTTPレスポンスが404になっているか確認してください。
特に多いのが、サイト内検索で情報が見つからないとき応答に200を使う場合です。
私は古くから啓蒙していますが、未だ対応されないサイトが多いです。
WordPressではなくても、一般サイトでも同じです。
日本を代表する上場企業が、こういった「恥さらし」をして商標価値を毀損することになりかねないのです。
ハッキングされたページ
Google公式ヘルプ
ハッキングされたコンテンツ
は、重要な内容が多いので一通り目を通しておいてください。
現在メジャーなハッキングは、検索エンジンに表示されたときだけハッキングされたサイトに転送する方式です。
特にSEOに敏感で無い企業の場合、自社のページの検索結果をクリックしたりしません。
そのため、発見が遅れてしまう事が多いです。
仕組みは、クローキングという方式を使います。
Googlebotには正常なサイト(高品質な企業ページ)を表示して、人間が検索結果をクリックしたときだけ感染ページへ転送します。
「人間」と「検索エンジンに表示されたものをクリックした」の二つの条件が重なるときなので、気付きにくいです。
ちなみに検索エンジンから来るクローラーには、正常ページを見せるので、検索エンジンも気づくのに時間がかかります。
私が言うといろいろ問題になりますけど、ひとつ言いますww
例えばchromeで利用状況を送信する事に同意していると、Googleはその情報をみて、同じURLでも別のコンテンツに転送されているのを発見できると思います。
つまり、利用者の多いサイトのクローキングは、すぐに分かってしまう訳ですね。
(この手法をGoogleが使っているかどうかは私は知りませんw)
Googleがハッキングによるクローキングを検出した場合、検索結果に「ハッキングされている可能性がある」旨を表示して検索者を保護すると同時に、大量に作成されるスパムコンテンツのインデックスを遅らせるため、クロールバジェットを極端に減らします。
ハッキングされた事を検索者に知らせ注意を喚起する
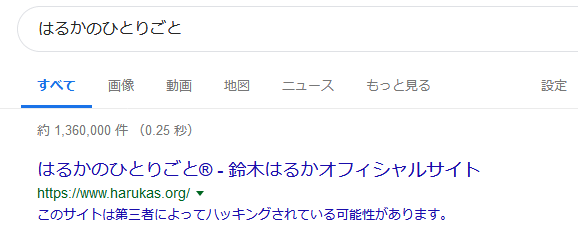
また、この時インデックスされるコンテンツは、リンク集、ワードサラダや他のサイトのスクレイピングなどで、非常に品質が低いです。
こういう低品質なコンテンツを発見した場合もクロールバジェットを減らしてインデックスを抑止します。
ハッキングされたサイトが、中々クリーンアップされないのは、クロールバジェットを減らされているからだと私は考えています。
日頃よりセキュリティに関心をもち、対策や確認を怠ることのないようにしたいですね。
無限のスペースとプロキシ
無限xxというフレーズが出てくると、クローラーは、困ります。
5.1、5.2に非常に近いと思います。
具体的には、カレンダーのパラメーターが、それに当たります。
サイドバーなどのウィジェットでカレンダーを表示していて、翌月のurlが「&y=2019&m=7」となっておりそれをクロールすると翌々月は「&y=2019&m=8」となります。
これには終わりがありません。
このような無限スペースは、クロールをやめてしまいインデックス対象にはなりません。
クロールバジェットを浪費してインデックスもされないという訳です。
無限の彼方へ?そんなの嫌です!
(↑米版公式ブログ:ブログタイトルは私による意訳)
こういう無限スペースを発見した場合、サーチコンソールにメッセージが行く様ですが、私は確認していません。
ブログでは対策方法が2つ提示されています。
(公式ヘルプの方がわかりやすく内容も濃いです)
1)robots.txtによるブロック
こちらはクロールバジェットの浪費を抑え、無限スペースを回避できます。
2)nofollowによるブロック
こちらは、クロールバジェットの浪費に効果はあまりないですが、長く続けているとクロールが減るので効果があると思います。
番外)URLパラメータの設定
これは私が考えついた案です。
URLパラメータを指定し、クロールしないという風にすれば、1)と同じ効果があると考えます。
私からはひとこと
こんなの設置しないでください
です。
次にtwitterなどでよく見る「無限スクロール」です。
こちらは、日本語版のブログがあります。
検索エンジンとの相性を考慮した無限スクロールのベストプラクティス
概要としては、無限ページを固定のパラメータリンク(相対ではない)で分割するという方式をベストプラクティスとして提示しています。
今は回線速度も速くなりモバイル中心の時代です。
何度も分割をクリックするより、ある程度の行を一気に読み込む方が、利用者に優しいです。
下手に分割するより、インデックスしたい分だけ固定(月単位とか日単位)で持つようにすれば良いのでは無いかとおもいます。
もちろん、どんなサイトで使うかによります。
私からはひとこと
こんなの設置しないでください
です。
例で出したtwitterは、おそらく専用のインデキシング機能を使っているのではないかと想定しています。
そう、IndexingAPIのような・・・
でないとこんなの出来ませんよね。
鈴木はるかのtwitterのSERP
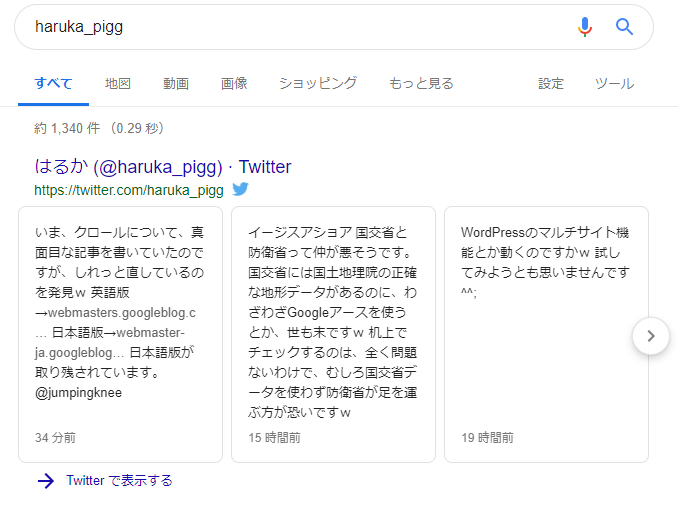
品質の低いコンテンツやスパムコンテンツ
ゲイリーさんの記事では、最後の項目となりました。
他サイトからスクレイピングされた情報や、自動生成されたコンテンツなど、価値が低いと判断されたコンテンツを掲載しているサイトやページは、クロールバジェットを減らされます。
検索結果に出す価値がないですから、インデックスさせる必要がないので、クロールさせる必要も無いという訳です。
詳細な事例や内容は、ウェブマスター向けガイドライン(品質に関するガイドライン)が一番近いと思います。
ウェブマスター向けガイドライン(品質に関するガイドライン)
下の方に13個の具体的な例が載っています。
おそらく、このほとんどがクロールバジェットに影響する内容だとおもいます。
対策としては、ひとことです。
ガイドラインを守ってください
鈴木はるかが考えるクロールバジェットの影響
私が、想定でクロールバジェットに影響するのではないか?と考えるものを羅列します。
念を押しますけど、公式ではないです(笑)
時間のかかるJS実行やDOM操作
現在のレンダリングエンジンは、chrome74相当(2019年6月8日時点)の機能を持っています。
かなり、高度なDOM操作をクライアント側で実行しても、クローラーは判別できるようになっていると思われます。
しかし実行に時間がかかったり、非常に広範囲の場所に要素を配置すると、解読できないばかりかクローラーのリソースを消費して得るものがない(インデックスできない)結果になります。
この場合、同様のページが複数あればページだけではなくサイト全体のクロールバジェットを減らされる可能性があります。
確かに便利になりましたがnoscriptでも、コンテンツが判別できるように構築したいです。
なお、レンダリングタイムアウトは、通常クロールで約20秒という実験結果が出ています。
これは最長であって、JSネストによる他処理やローディング(サーバー処理時間)のクリティカルパスによっては、実際の実行時間が10秒でもインデックス出来ない可能性があります。
インデックスできないということは、クローラーからみれば無駄足ですよね。
無駄なサイトにクロールの労力を割くわけが無いので、クロールバジェットを減らされると考えています。
現在は、JSを利用したサイト向けにも、各種試験(モバイルフレンドリーテストやURL検査など)が充実しているので、振る舞いをクローラーの目から充分に確認してください。
検索に関連したJavaScriptの問題を修正する
(タイトルの翻訳は私による)
4xx/5xxのエラーを返すこと
404/410は、クローラーがアクセスしたURLのコンテンツを、削除した事をGoogleに知らせます。
通常運用でも発生することであり、何か問題がある訳ではありません。
クローラーに4xx(コンテンツ削除、アクセス制限)を返したコンテンツが、その後どうなるかです。
1)ステップ1
通常のページと同様の速度でクロールを行い、発見後アルゴリズムの判断で404が検出された事を内部処理
2)ステップ2(~1day)
間違いで無いと判断したら検索結果から削除
3)ステップ3(~1m)
この間URLを復元すると、ほぼ元の順位に戻る
4)ステップ4(1m~)
クロールバジェットを徐々に減らされていく
ただし完全にゼロにはならない
削除:404/410とアクセス制限:403/401の動きを簡単にまとめたら、以上のような感じです。
503/500(サーバーエラー/サービス利用不可)
1)ステップ1(~1w)
高頻度で、再クロールを実施
2)ステップ2(1w~1m)
パーマネントエラーでインデックス削除
クロールバジェットは404レベル
この間URLを復元すると、ほぼ元の順位に戻る
3)ステップ3(1m~)
クロールバジェットを徐々に減らされていく
ただし完全にゼロにはならない
こうしてみると、サイトを一時中断するときは、404は使用せず503がベストだというのが分かります。
また、概ね一ヶ月を超える期間でその状態にしていると、徐々にページの価値は失われ、クロール回数も減っていきます。
サイトの状態やコンテンツをどうしたいのか、よく考えてクローラーに返却するコードを選んでください。
矛盾をしたサイトマップを送ること
私の記事を全て読んだなら、サイトマップとサイトマップ更新Pingがどれだけ重要か分かると思います。
サイトマップに矛盾する内容を入れていたらどうなるかです。
例えば、robots.txtでブロックされているURLをサイトマップで送信したとします。
クローラーは、サイトマップに書かれたURLでクロールを行うとしますが、robots.txtでブロックされているためできません。
このような行為は、該当URLのクロールバジェットを減らされるどころか、サイトマップを信用しなくなるかもしれません。
通常運用にてlastmodで時刻を指定したURLに対して、robots.txtでブロックするような奇妙な人はいないとおもいます。
このような運用は避けたいですね。
矛盾のある組み合わせ(以下をサイトマップで送信)
・robots.txtでブロックしているページ
・noindexページ
・エラーページ(5xx/4xx)
・重複ページ
・canonical元(※)
・301リダイレクト元(※)
(※)一時的(1ヶ月以内など)ならクロールを促進しサイトの構成変更に対応
noindexを使うこと
noindexは、検索エンジンに対しての絶対命令で、コードが正しく解読された場合、URLに付随する情報は検索結果から削除されます。
とても強力な命令です。
メタタグで、htmlに書き込む事も出来ますし、クローラーのHTTPリクエストに対して、HTTPヘッダのレスポンスにnoindexを指定する事も出来ます。
この命令は、インデックスの削除です。
実行され次第、クロールバジェットは減らされていくと思います。
そのURLに対して、インデックスの必要がありませんので、クロールすること自体も無駄になるわけです。
唯一のクロール目的はnoindexが外されたか?をチェックすることです。
しかし、外されたとしてもクロールバジェットが減らされているので、検出するのに多くの時間が消費されるでしょう。
その場合は、サーチコンソールのURL検査で当該URLの更新リクエストをするのも手だと思います。
頻繁にnoindexとindexを繰り返すという運用は向かないので、そういう使い方をしないでください。
私は、日付archiveなどnoindexにしています。
一度も戻したことはないですね^^;
別のページを実装すること
クロールバジェットは、クロールの割り当て量です。
サイトのタグで、1つのページから複数のページへ分岐する場合、クロールバジェットを消費します。
例えば、1000ページの中規模サイトを持っており、全ページにメタタグで英語をの翻訳版を追加したとしたら、2000ページになってしまいます。
さらにレスポンシブでは無くモバイルとPCで別のコンテンツにした場合、4000ページになります。
一気に大規模サイトの仲間入りかもしれません。
たった1000コンテンツしかないのに、alternateで別のページを実装することでこのような状態になります。
新規で中規模サイトを設計するときは、レスポンシブは必須としてどんな言語を実装するのか、ガラケーはどうするのかなど、充分な設計が必要です。
クロールの統計情報を俯瞰する
いろいろなサイトの統計情報や、自分の実験で分かった事があるので、見方を想定してみます。
まず、サイトの総量であるクロールバジェットの上限になっているか否かは、一般的なサイトでは分からないです。
クロールの統計情報で分かるのは、サーバーのパフォーマンスとクロールレートの試行錯誤です。
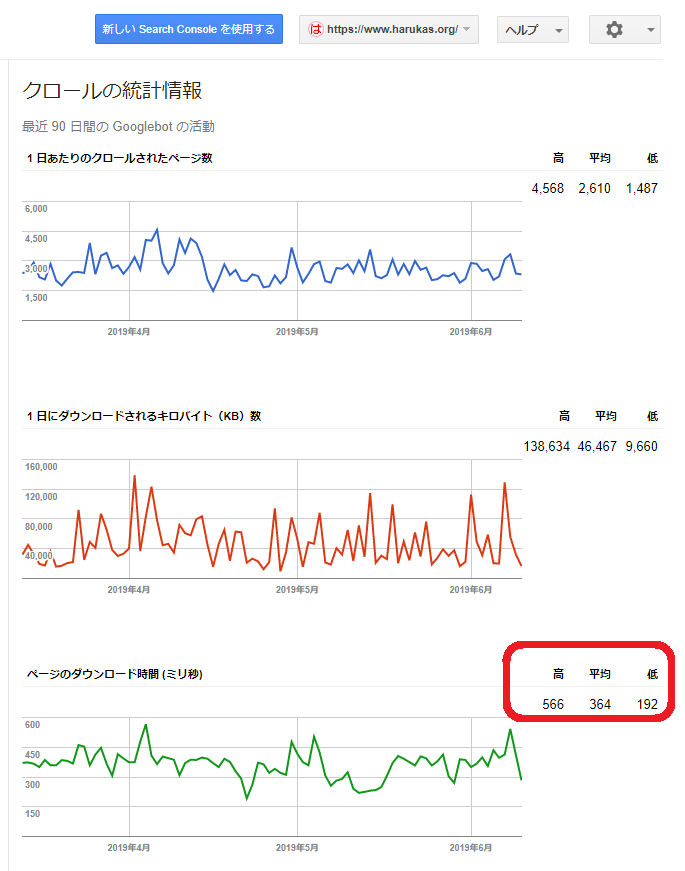
特徴として、次を挙げさせてもらいます。
・高速なサイトはページ数がなだらかできめ細かい
・低速なサイトはページ数がギザギザで高低が激しい
・高速なサイトはダウンロード時間がなだらかできめ細かい
・低速なサイトはダウンロード時間がギザギザで高低が激しい
またダウンロード速度の平均値は、2000以内になっていることが望ましいです。
では、なぜ遅いサイトは、ノコギリの歯のようになるのでしょうか?
それは、クローラーが沢山クロールしたいのにできないからです。
クロールレート上限まで行く→調整してゆっくりになる
この繰り返しのため、ギザギザになるものと思われます。
ダウンロード速度は2秒以内を目指し、サイトのパフォーマンスを調整することは、閲覧者を増やし、コンバージョンを増やすことに繋がりますので、もしパフォーマンスに問題があるようであれば、すぐにできる対策なので実施した方が良いでしょう。
パフォーマンスは、ランキングに直接影響はありません。
しかし、好まれるサイトは上位に行きやすいので、結果的に早いサイトが上位になっていることも、統計上明らかです。(サイバーエージェント木村氏の調査より)
harukas.orgのクロールの統計情報(古いサーチコンソールのみ)
サイトが早すぎて文句を言われるのを聞いたことがありません。
遅いサイトはクロールレートに影響します。
しかし、それよりも訪問者に対するエクスペリエンスの向上を目指したいですね。
ECサイトで商品が品切れの時のベストプラクティス
twitterで、ジョンさんがECサイトの運営者と話していた内容です。
質問者は、在庫があるときはindexで無い時は、noindexにしていました。
これについてジョンさんは、noindexとindexを交互に繰り返す手法は良くないと言いました。
noindexは、該当のURLを削除してインデックスしない命令です。
それなのに、一時的に品切れだからと言って、noindexにすると、実際に入荷したときインデックスされない(時間がかかる)可能性があります。
こういう矛盾のある行為は避けた方がよいでしょうね。
では、品切れの時のベストプラクティスは何でしょうか?
2020年1月オフィスアワーで、ジョンさんが回答を出しました。
しかし、どれがベストかという回答を控えました。
在庫が無い場合は、以下の2パターンが考えられます。
・代替商品がある場合
→リダイレクトを行うことで既存のページ価値を維持できるし、訪問者に良い体験を与える
・代替商品が無い場合
→品切れのhtmlを記述(現在品切れです等)
→構造化データのマークアップ(はるか注:availabilityのマークアップ等)
→404の返却
→場合によってはnoindex(はるか注:二度とその商品を置かない場合のみ)
※代品が無い場合は、サイトの規模や運営者の意図に依存するという感じで、これだ!という回答は出ませんでした。
想定通りの内容でした。
以下は、私が買う立場だった場合の想定です。
・概ね一ヶ月以上経つと品切れでrobots.txtでブロックなどを行う(404でも良いでしょう)
・入荷の予定があれば入荷日/予定を書きインデックスする(ファンの店ならこれが一番)
こんな感じですかね。
入荷の予定が無いのに1年間売り切れとかはやめてほしいですw
まとめ
クロールは、SEOの基本です。
そのクロールがどんな条件で何を判断してどのくらい行われるかをまとめてみました。
最後に繰り返します。
クロール数とランキングは別物です。
・クロールバジェットが足りてないと思われる
・クロールレートが非常に低く設定されている
などを問題とする場合、その影響をしっかり考えてください。
決して検索順位が変わることでは無いので、対応の優先順位の付け方には注意してください。
では、皆様の知識の向上に役立てたなら幸いです。
鈴木はるか

コメント